
2024 “龙芯杯”
——概述
前言
似乎从大二上过数字逻辑,写过 CPU 大作业后,我就踏入了这条不归路。
暑假,我们借了教室。从单周期 CPU 开始,到完成所有中断例外,不过两周,而离提交却还有三周左右。此时只剩 AXI I/F 没有完成,看起来一切顺利。我认为自己水平足够,也许是之前的内存保证了一定可以在下一周期返回的缘故,选择了跳过书中建议的先实现类 SRAM I/F,直接将没有握手信号的 SRAM I/F 接到了一个 AXI 转接桥上。这个行为成为了我这三周痛苦的根源。事实证明:
在没有绝对的经验与把握的前提下,不要试图忽视任何成熟的建议与警告。也不要好高骛远,眼高手低,过于追求完美。
“得益于”未经过思考写下的交互与流水线控制逻辑,整个 CPU 在加上 AXI I/F 后摇摇欲坠。任何修改都可能让 CPU 跑飞,更不用说添加更复杂的逻辑。此外,初学者用一个月的时间显然无法完成一个 AXI I/F 的 CPU,更不用说 LoongArch32R 几乎没有什么资料可以参考(于 2023 年 8 月)。
之后,我们似乎过于追求一个部件的完美,而忽略了整体的协调。我们采用了一款性能非常优秀的除法器:主频高、运算快。那是一个支持 110MHz 主频,平均 3 周期以内可以输出的整数除法器。我们认为这个除法器一定会给我们带来巨大的收益,但当我们发现每一次访存,无论是取指令还是取数据,都会被加上 25 周期的延时后(这个延时在 2025 年被加到了 150 周期),除法运算省下来的时间可以忽略:这对于性能测试没有帮助,除了可以在报告中写上一笔,还是使用别人写的模块。
过了这个假期,我决定从主要矛盾入手,提升性能。于是,一个 dcache,我写了几周。当想要做一些自己的事时,总是被各种杂事缠身,当然,也可能是我对这个事情很害怕,试图用各种事情掩盖过去,直到一个不能再拖的时候,才会开始动手。
又是一年新年,回家之后非常自由自在。吃饭,睡觉,穿插着写代码。于是我的第一版带 cache 的 CPU 就这样完成了。我叫他 Hades,也许是受尽了 cache 的折磨,或者是受尽了 CPU 的折磨,所以叫他这个名字。
We named it “Hades”, the god of the underworld For a long period, it has been experienced, unmoved by prayer or sacrifice. In such an unseen depth, freezing, dark and empty, there are few persons, individuals, mortals, who could not feel despair. Like a forbidden area - one great Furnace flam’d, yet from those flames no light, but rather darkness visible serv’d only to discover sights of woe, regions of sorrow, doleful shades, where peace and rest can never dwell, with ever-burning Sulphur unconsum’d, we stepped into and fought with, whereas failure takes the throne, where divine light will never spread.
又过了一个学期,又是缝缝补补的一个学期,害怕做一些实质性的更改,不敢去做,不敢去想,只想做一些机械性的工作,完善现在的项目,整理现在的项目,但是显然没能成功。各种事让我无法思考,编码工作也就随之停滞了。
拖延症拖到最后总要付出一些代价,不是身体上的折磨就是心灵上的折磨,或者两者兼有。临近比赛截止日期,也就是六月下旬,我们正式开始了这次的备赛工作。这个去年的时间差不多,但区别是我们已经有了一个自行设计的,完整的 CPU 核,还有 tlb、cache 等模块,也有了丰富的设计经验,去年只是空有一颗参赛的决心而已。显然,决心没有用,也不要想能够抄一份代码。在 CPU 核的极高耦合度下,没什么东西是开箱即用的;经验才有用,可能一个 bug 需要没有经验的人找一个星期,有经验的人一眼就能看出来。我很喜欢一个同样参加过龙芯杯的学长的感受:
该踩的坑,一个不少,该走的路,一米不差
临近提交时,我们完成了超标量的设计,这个设计并没有我们想象的那么难。为了提升频率将跳转单元挪来挪去,改来改去。最后算是交上了一个还算满意的版本。也算是给这么长时间的努力一个交代。
进了决赛,去了重庆(见龙芯杯三日游),答辩过后依旧兴奋,直到第二天的颁奖典礼过后才冷静下来。拿了二等奖,破了学校记录,还是非常心满意足的。比赛一年比一年难,从最开始的完成即完赛,到现在标配 cache,不敢想象过两年是不是要标配多发射了。不过我能做的,就是把参赛的 CPU 写好注释,写好文档,让他可以传承下去,让更多人能够学会设计 CPU,调试 CPU。
2024 年 8 月 (修改于 2025 年 8 月)
学院路
CPU 设计
CPU 设计看似简单,实则复杂。
看似简单,是因为设计 CPU 的大部分原理都很浅显易懂;说复杂,是因为每一个环节都不允许有差错:一个周期的错位就会导致 CPU 跑飞,轻则运算出错,重则完全卡死,动弹不得。所以 CPU 设计十分严谨,或者说计算机体系结构这个学科是十分严谨的。在实验过程中,一定要细心、考虑周全。不要认为 CPU 可以依靠 BUG 运行。一个 RTL 代码中的 BUG 没有发现,当它变成芯片上的电路时,付出的代价就是以百万计的了。
CPU 从复杂程度来看,可以简单分为单周期、流水线、超标量几种。大部分计科学生都应该会在《计算机组成原理》这门课上学到如何设计一个单周期与流水线 CPU。但这还离实现一个“可用”的 CPU 有着不小的距离。
在计算机中,时刻充满了 trade-off:折中,或是妥协。常用的 DRAM 内存每隔一段时间需要刷新数据,而 SRAM 则不需要,代价是晶体管数量的增加、成本的增加。CPU 访问内部寄存器只需要短短的一周期,而访问 DRAM,在时延上相较寄存器有着很大的差距。因此,我们用访问延迟相对较低的 SRAM 构建片上 cache,在高速的寄存器与低速的内存之间架起一座桥,一座透明(transparent)的桥。
从性能上来说,cache 对处理器性能的提升是巨大的。在龙芯杯提供的 SoC 上,没有 cache 的 CPU 几乎无法启动可用的任何现代操作系统(除非你可以忍受极长的启动时间,并且敲下一个字符后等待几秒字符才会出现在屏幕上)。从“龙芯杯”,国内本科生处理器设计的顶级赛事,的举办情况来看:前几届实现了流水 CPU 就能够入围决赛,如今办到了第八届,完成双 cache 已经成为了进入决赛的隐形条件。没有 cache 就意味着相同架构下性能只有别人的几十分之一(现在几乎成了百分之一了),即便进了决赛也只可能是三等奖。从功能上来说,TLB 也是处理器启动系统很重要的一环。没有 TLB 在启动系统时就会更加困难,需要自行配置一个可以运行在无 TLB 环境下的系统。
下面我将会从单周期 CPU 开始,详细介绍如何设计一个支持 LA32R 指令集的,近乎“可用”的 CPU。
图灵机
为了更好地理解一个 CPU 需要做什么,我们将一个 CPU 以及与其交互的内存粗略地视为一个 图灵机(Turing Machine)。
一个图灵机是一个七元组 \(M = (Q, \Sigma, \Gamma, \delta, q _{0}, B, F)\) ,其中:
- \(Q\) 是一个有限状态集合;
- \(\Sigma\) 是一个输入字母表;
- \(\Gamma\) 是一个纸带字母表,\(\Sigma\subseteq\Gamma\);
- \(\delta\) 是一个转移函数;
- \(\delta\) 有两个参数,一个状态 \(q\in Q\),一个纸带符号 \(Z\in \Gamma\);
- \(\delta(q, Z)\) 要么未定义,要么是一个形如 \((p, Y, D)\) 的三元组:
- \(p\) 是一个状态,\(p\in Q\);
- \(Y\) 是一个纸带符号,\(Y\in \Gamma\);
- \(D\) 是一个方向,要么是 \(L\) 表示方向向左,要么是 \(R\) 表示向右。
- \(q _{0}\) 是一个起始状态,\(q _{0}\in Q\);
- \(B\) 是一个空符号,\(B\in \Gamma - \Sigma\);
- 除了输入以外其他的纸带部分初始都为空。
- \(F\) 是一个终止状态的集合,\(F\subseteq Q\)。
我们将 CPU 的状态集合视作 \(Q\),内存视作纸带,CPU 执行指令视作转移函数 \(\delta\),程序结束则为终止状态。现在,我们可以将 CPU 视为一个黑盒,这个黑盒只会接收由字母表 \(\Sigma\) 中字母所构成的字符串的集合 \(\Sigma^*\),即程序;CPU会根据当前状态和纸带上的字母做出对应动作:改变自己的状态到 \(p\),向内存中写数据 \(Y\),并向左或向右移动。当 CPU 停机时,便执行完了他的输入(也就是程序)。
综上所述,为了执行程序,我们需要:
- 获取状态 \(q\);
- 将状态,输入二元组映射到三元组: \(\delta(q, Z) \mapsto (p, Y, D)\);
- 转移状态,并回到1。
即,取指令,译码(映射到操作),和执行等三部分。
事实上,编写 brainfuck 语言的代码便是人肉模拟图灵机,理论上可以与其他高级语言做到同样的事(相信你不会想这么做的),比如这里便是一个计算斐波那契数列的程序。
单周期处理器设计
单周期处理器,虽然简单,但却是入门必备之良品:你可以从中学到一条指令在处理器中是如何被取回、译码并执行的,你也可以用这个单周期处理器实现许多许多功能,比如驱动 VGA 或是算一个斐波那契数列,也可以完成一个贪吃蛇,弹球游戏,都是没有问题的。
一个处理器想要正常工作,以下几个模块是不可或缺的:一个负责取指令的模块(取指模块)、一个负责解释指令需要做什么的模块(译码模块),以及一个负责执行译码模块给出的结果的模块(执行模块)。当然你也可以把他们写在一个模块内,当然我们不推荐这种写法。这种写法会对后续的优化带来一定的麻烦。一定的代码规范对于任何人而言都是有益的。
现在,我们可以画出一个 CPU 的顶层模块设计图:
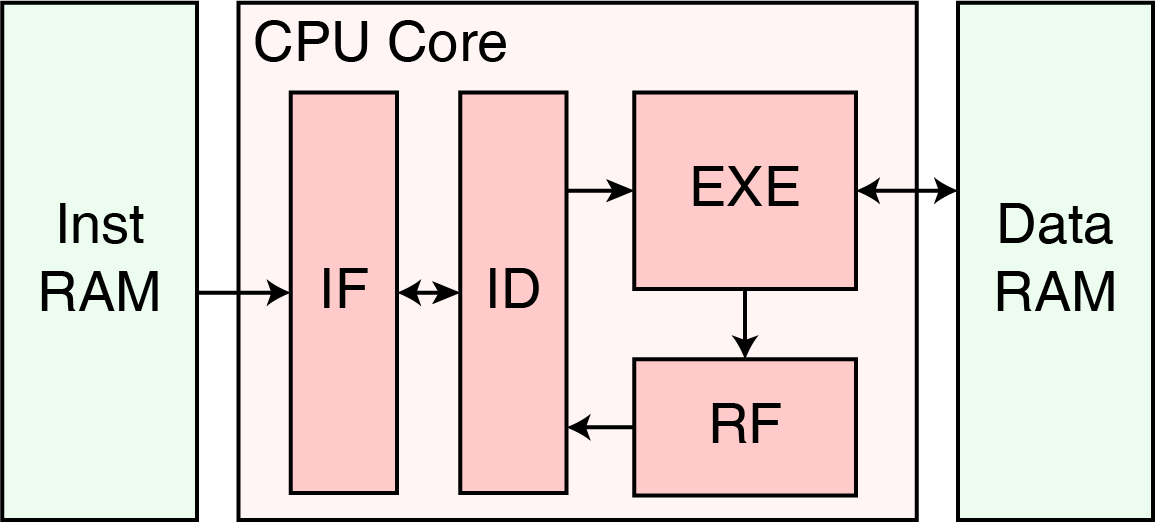
其中,Inst RAM 是负责存放所有指令的随机存储器,Data RAM 是负责存放数据的随机存储器。在 CPU Core 中,Instruction Fetch(IF)是取指模块、Instruction Decode(ID)是译码模块、Execute(EXE)是执行模块,Reg File(RF)是寄存器堆。
Inst RAM 与 CPU Core 之间通过 RAM I/F(RAM Interface,即 RAM 接口)连接,CPU Core 与 Data RAM 的连接同理,IF 与 ID、ID 与 EXE 之间通过多位宽的数据、控制线进行连接,EXE 与 RF 通过 RF I/F 连接。
在 CPU Core 复位后,IF 首先向 Inst RAM 发送读请求,在同一周期 Inst RAM 返回给 IF 指令信息。此时,IF 通过数据线将指令送至 ID 中。ID 负责译码该指令,同时根据译码得到的寄存器信息从 RF 中读取操作数,并将控制信号和数据信号一并送至 EXE 中。EXE 负责译码 ID 传来的控制信号并执行:当指令需要读内存时,EXE 会通过 RAM I/F 与 Data RAM 交互,得到 RAM 中的数据,并负责写入 RF;当指令需要写内存时,EXE 会通过 RAM I/F 与 Data RAM 交互,向 RAM 中写数据;当指令与 RAM 无关时,EXE 会负责写入 RF,或什么都不做。
取指模块
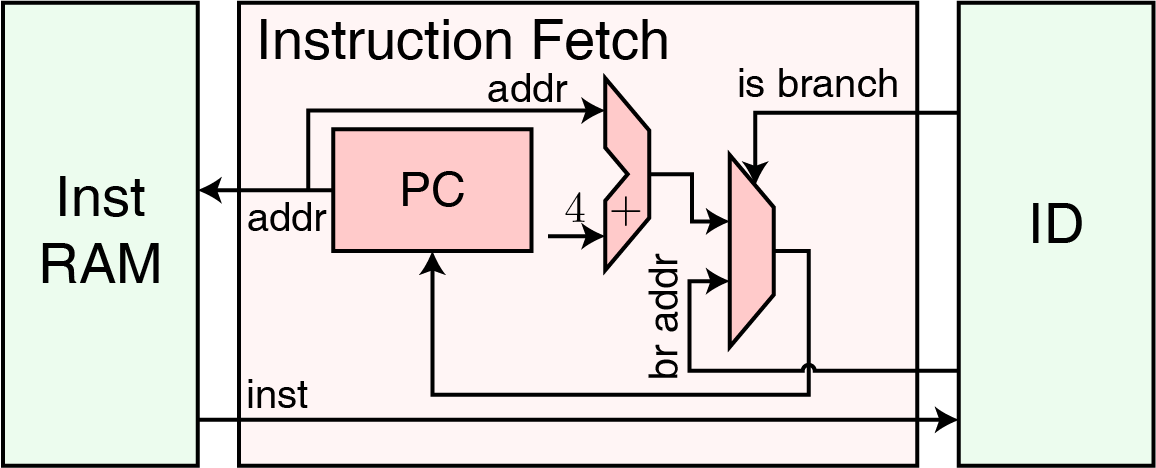
取值模块负责取出程序计数器(PC)中的值 PC,作为地址 addr 送到存储器中,并从存储器中取回地址 addr 所对应的指令 inst。如果把以上的过程写成伪代码,将会是这样:
extern uint32_t RAM[1024];
uint32_t inst;
inst = RAM[PC];
在每次取值后,若没有跳转指令正在执行(即 is branch 为 1),PC 的值将会自增一个指令长度(具体自增的值取决于指令集和外设的寻址单位,例如一个拥有 32 位定长指令的指令集,存储器按字节寻址,PC 的值一般会自增 4),从而实现顺序取值,否则 PC 会被置为 br addr 的值,从而完成“跳转”。如果把以上的过程写成伪代码,将会是这样:
extern bool is_branch;
extern uint32_t br_addr;
uint32_t PC;
if(is_branch){
PC = br_addr;
}else{
PC++;
}
译码模块
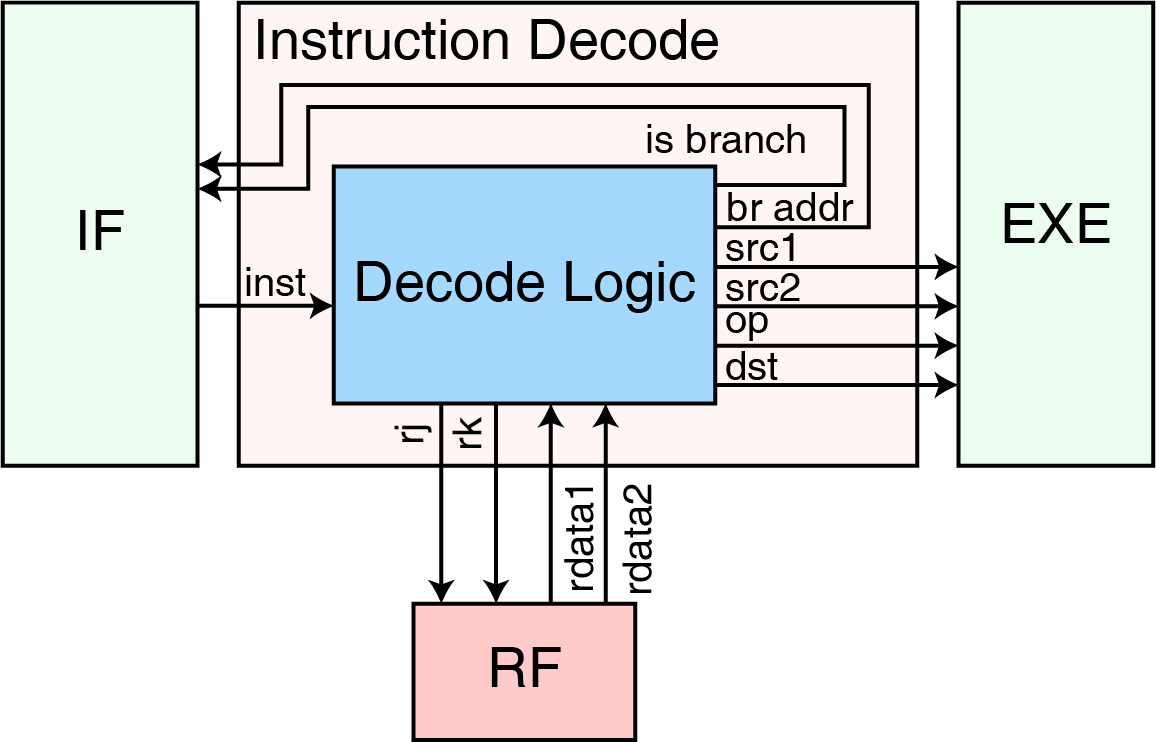
译码模块负责将取值模块取出来的地址进行解释,并“指导”执行模块需要做什么。我们已经在上文中看到了信号 is_branch 和 br_addr,这两个信号就是在这里生成的,用来指导取指模块 PC 的更新。除了这两个信号,译码模块还会生成大量用于控制执行模块计算的信号,如译码模块加法指令就会产生两个操作数、一个计算类型和一个寄存器写地址(如果该指令不需要写寄存器,则将写地址直接置为 只读寄存器 0):
extern uint32_t inst;
extern uint32_t regfile[32];
uint8_t dst;
uint32_t src1;
uint32_t src2;
OP_TYPE op;
if(is_addw(inst)){
op = ADDW;
src1 = get_src1(inst, regfile);
src2 = get_src2(inst, regfile);
dst = get_dst(inst);
}else{
//...
}
执行模块
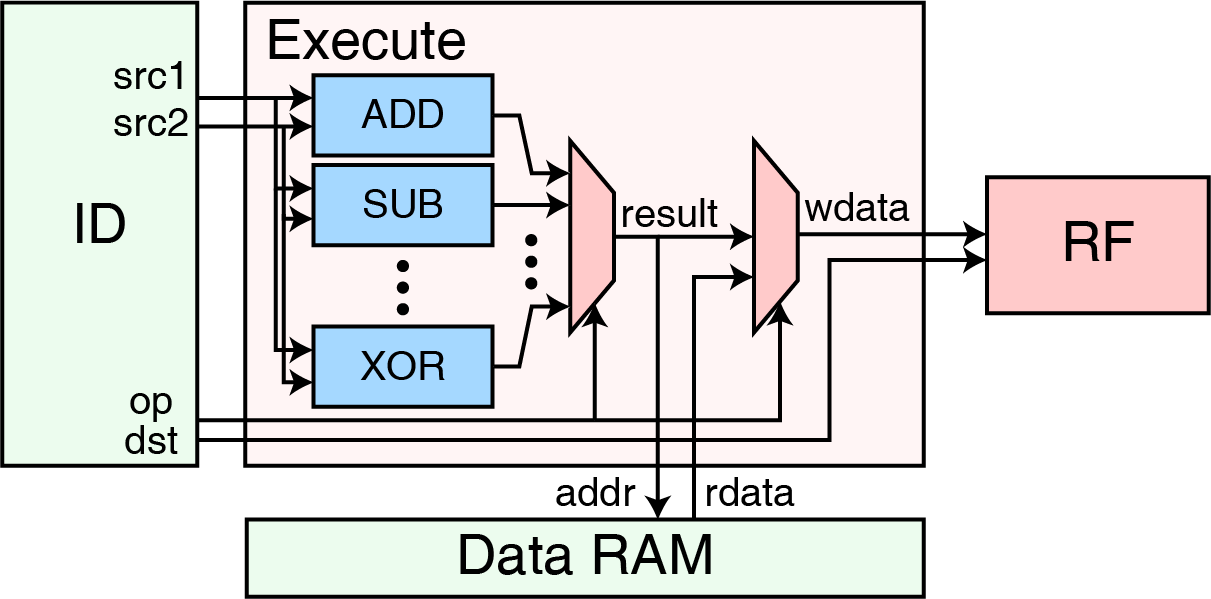
执行模块接受译码模块的指导,执行取回的指令。继续以加法为例,执行模块会根据译码模块产生的计算类型确定需要对两个操作数进行何种计算(如加、减、乘、除等),并且在我们的 CPU 中,执行模块负责根据传来的寄存器写地址更新寄存器堆。
extern OP_TYPE op;
extern uint32_t src1;
extern uint32_t src2;
extern uint8_t dst;
extern uint32_t regfile[32];
uint32t result;
switch(op){
case ADDW:
result = signed_add(src1, src2);
break;
// ...
default:
break;
}
write_reg(regfile, dst, result);
流水线处理器设计
早在上百年前,人们发明了“流水线”。1959年,人们第一次在通用处理器——IBM 7030 Stretch 上应用了流水线技术(Pantazi-Mytarelli, 2013)。
我们在上文已经介绍过了单周期处理器,和如何设计一个极为简单的单周期处理器。实现一个单周期的处理器固然简单,但也有一定代价。在这些代价中,最令我们不能忍受的一个便是“性能”。我们为了简单考虑,只使用“每个单位时间内平均执行了多少条指令”这个性能指标来衡量一个处理器的性能(Performance):
\[\text{Performance} = 1/D\]其中 \(D\) 为处理器的执行时间。
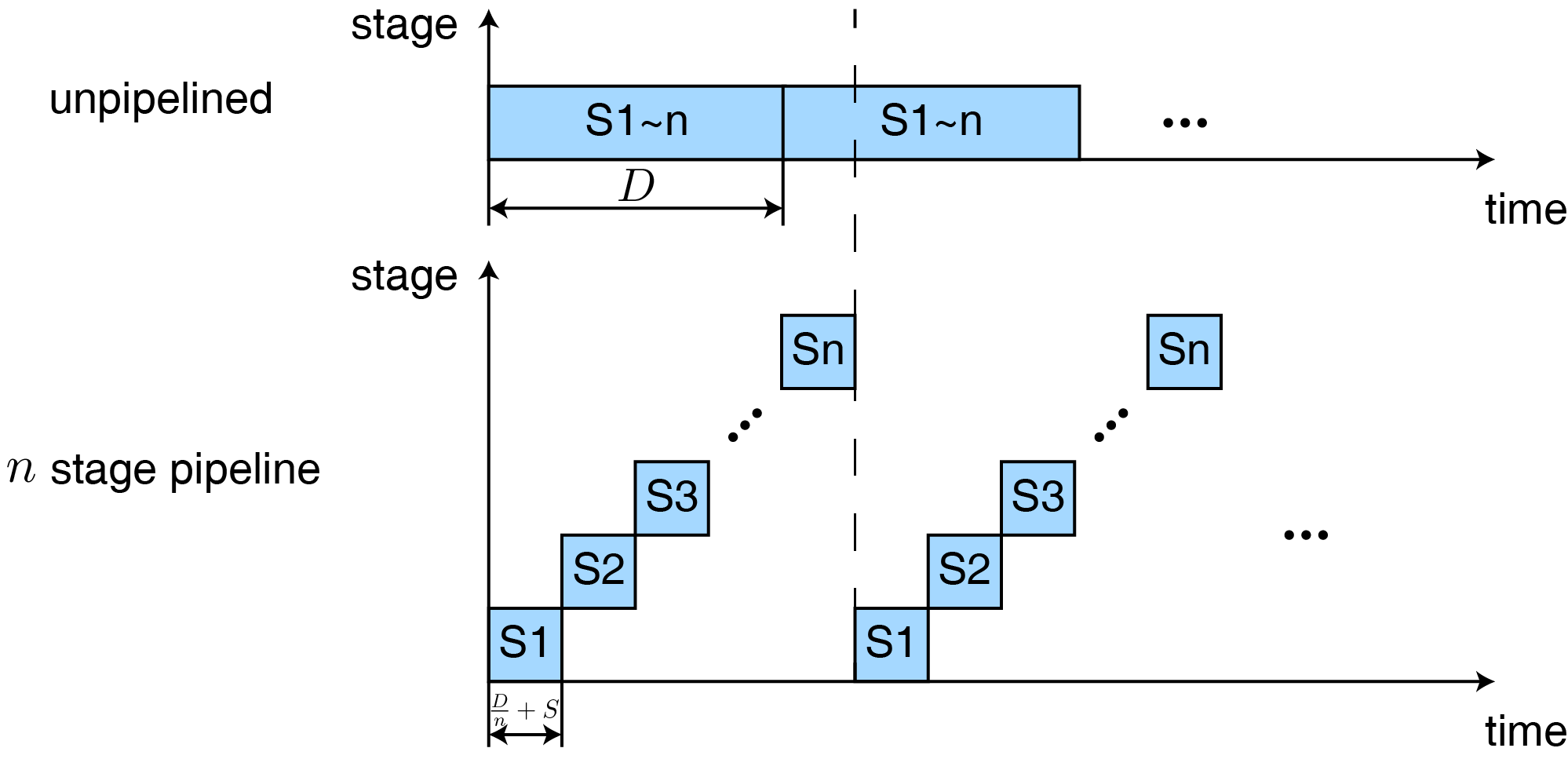
单周期处理器的性能是执行时间 \(D\) 的倒数,如果我们缩减执行时间,就可以获得更高的性能。对于一个拆分为 \(n\) 级的处理器来说,理想情况下每一级的执行时间会是 \(D/n\),考虑每一个之间寄存器的建立延迟为 \(S\)。现在,执行一条指令的时间为 \(n(D/n+S)\),性能为 \(\text{Performance} = 1/n(D/n+S) = 1/(D+nS)\),相较单周期处理器反而下降了。但当我们画出这个处理器执行指令时的“时空图”就会发现在一条指令的执行时间 \(n(D/n + S)\) 内,每一级只会有 \(D/n+S\) 的时间在执行指令,其余时间都是空闲的,这就造成了显著的浪费。如果我们将这些空闲时间有效利用起来,我们就能实现既定目标,获得更高的处理器性能。

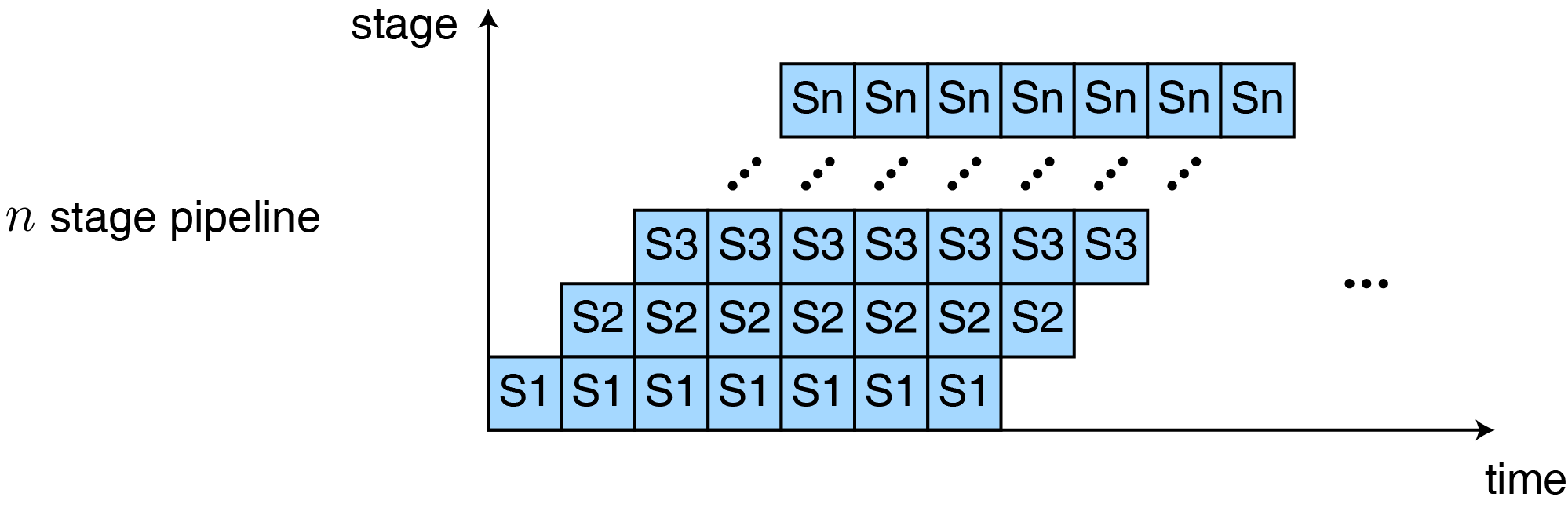
假设我们每间隔 \(D/n+S\) 便向处理器中输入一条指令,每一级部件都可以完成自己的工作,并按时送到两级部件之间的寄存器中,这样第一条指令的执行时间还保持 \(n(D/n+S)\) 不变,但随后每隔 \(D/n+S\) 便会有一条指令执行完毕。这个处理器的性能为
\[\text{Performance} = \frac{1/n(D/n+S) + (I-1)/(D/n+S)}{I}\]其中 \(I\) 是执行的指令数。当 \(I\to \infty\) 时,有
\[\begin{aligned} \text{Performance} &= \lim_{I \to \infty}\frac{1/n(D/n+S) + (I-1)/(D/n+S)}{I} \\ &= (D/n+S)\lim_{I \to \infty}\left(\frac{I+n-1}{I}\right) \\ &= 1/(D/n + S) \end{aligned}\]当 \(S\) 足够小时,几乎是单周期处理器性能的 \(n\) 倍。
References
Cui, C. (2024). 形式语言与自动机. https://fla.cuijiacai.com/07-tm/.
Pantazi-Mytarelli, Iro. (2013). The history and use of pipelining computer architecture: MIPS pipelining implementation. 1-7. 10.1109/LISAT.2013.6578243.
姚永斌. (2014). 超标量处理器设计. 清华大学出版社.